
關於離開 Threads 之後
收入下跌 , 但取回自己的注意力


上星期公開宣佈離開 Threads 之後,收入明顯下跌。這件事其實十分自然——Substack 本身的讀者基數並不算大,少了 Threads 這條觸及新讀者的管道,增長速度必然減慢,這個落差我早已預料到 。
但相對地,我換回來的東西其實更為珍貴——我終於取回自己的注意力。不再被無聊的 feed、演算法、即時回應機制牽着鼻子走,我可以將全部心力投放於幾件真正重要的事:寫更好的文章、做更好的產品。
成效反映得非常直接。短短幾日之內,我已連續完成三次重大系統升級,今次的更新 只是其中之一。這種生產力密度,在以前每日花幾個鐘頭在社交媒體上「嘴炮」的日子,是無論如何都擠不出來的。
或許這條路不會令我大富大貴,Substack 的 ceiling 亦擺明在那裡。但我有一種非常踏實的感覺——我正在一條正確的路上走着。而各位仍然留下、甚至付費支持的讀者,就是令我相信這條路走得通的最大理由 。
三次升級的脈絡:從 Agent 到系統,再到 Evidence Quality
這幾日連續完成的 v1、v2、v3 三次升級,想用最精簡的篇幅交代一次,讓各位知道系統是如何一步一步走到今日這個形態。
Version 1:從 GPU skill 遷移至 CPU codebase
這是整個系統真正的分水嶺,亦是我過去這一年最重要的一次心態轉變。
舊版是一個 agent 食盡所有工序——Dispatcher 觸發後,單一 LLM context 在同一個 prompt 裡同時處理一棵樹上十幾條 hypothesis,從抓新聞、分派證據、下 verdict,到寫 conclusion、組 Slack 訊息全部包辦。跑得越久問題越明顯:hypothesis 之間 cross-contamination、記憶只能靠 context 硬撐、對讀者而言是個黑盒、整條 pipeline 與 agent 綁得太死 。
新版則搬到 GitHub 一個 /stock-trees repo,每隻股票一個資料夾,每條 hypothesis 一個 JSON。整條 pipeline 改寫為 deterministic Python,LLM 只負責第 3 步的 judgment,前面抓新聞、分派證據、後面 schema validation、git commit、推 Slack 全部由 CPU code 處理。每條 hypothesis 獨立開一個 LLM call,餵入我稱為 judgment_pack 的 payload(baseline data + 上次 conclusion + past evidence summary + 本週新 evidence,約 33KB),context 互不干擾,判斷銳利度明顯提升。
AI 是一個很強的 component,但它不是整個系統。分層、隔離、可觀察、可重做、可回溯——這些工程本份,deterministic code 做得比 LLM 好。
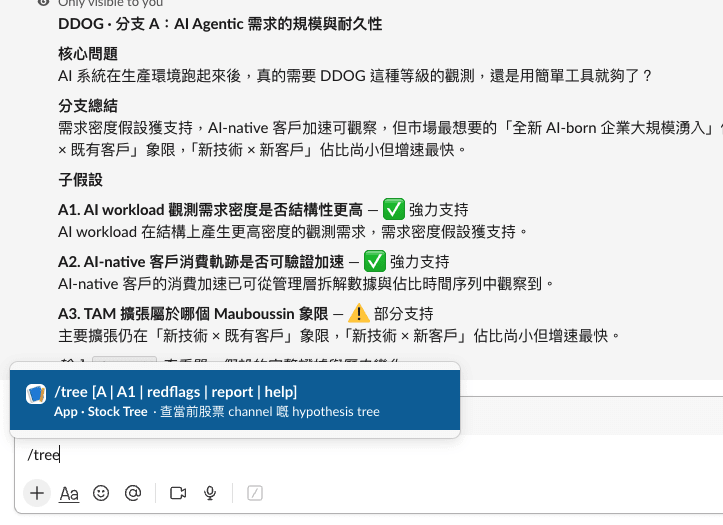
Version 2:Stock Tree Bot 與 /tree 指令
v1 把骨架穩住之後,我再加入了 stock tree bot。讀者在 Slack channel 輸入 /tree 指令,即可即時拉出當前股票 channel 的 hypothesis tree,詳細閱讀每棵樹的葉(hypothesis)、枝幹(pillar)、歷史(verdict evolution) 。
這個改動表面上只是多了一條 slash command,實際上是把原本只能在 weekly update 長文裡線性閱讀的內容,變成可以按需查閱的互動式結構。讀者的反應亦相當正面 。
🚀 v3 升級:Two-Pass Hybrid Pipeline
有了 v1 穩定的 CPU 骨架、v2 的互動介面,今次終於有條件處理更深一層的問題——evidence quality 本身。
這次升級之所以能夠落地,說到底並非靠我一個人。是各位付費訂閱的讀者,實實在在地支撐起整條 pipeline 的運算成本,令我可以相對「任性」地去揮霍 tokens、做 A/B、跑 pilot、反覆調校 prompt。換作一年前獨力支撐的我,這種規模的實驗根本無從談起。所以——真心多謝每一位讀者。你們支付的並非只是一份 newsletter,而是讓一個 90 後 PM 能夠花費鉅量金錢去打造產品的底氣。
為何要做這次升級?
即使 v1 已經把每條 hypothesis 的 context 隔離開,今次 audit 仍然發現 Weekly Update 在證據檢索層面有兩項結構性問題:
1. Source Quality 污染
上週完成 source tier audit 後,發現 cited evidence 之中有 20.3% 來自 T4 來源(Threads 貼文、LinkedIn 個人帖子、vocus、bingx、tradingkey 等社交媒體/部落格/聚合平台)。甚至連本人的 Substack 都曾經被系統引用為 evidence,形成 self-reference loop——這條 loop 我無論如何都不能容忍它繼續存在。
2. Verdict 表達力不足
舊有的 3-value 詞彙(supported/partially_supported/challenged)過於粗略,無法區分「趨勢正面但尚未驗證」與「已確認驗證」之間的差別,亦難以呈現「接近 falsification」的早期預警信號。
新版本帶來什麼?
① Two-Pass Hybrid 檢索架構
每個 hypothesis 獨立執行四階段流程:
Pass 1:Tavily 廣泛搜索(含 35 個低質 domain 黑名單過濾)
Pass 2:Ai Agents 制定針對性查詢計劃
Pass 3:Tavily 精準補充檢索
Pass 4:Ai Agents 結構化判決(anchor-preference prompt)
每個 hypothesis 擁有獨立預算,不再共用同一個受污染嚴重的 evidence pool。
② Verdict 細分為 6 級

新增的 🟢 / 🟠 / 🟡 三個層級,令 thesis evolution 的梯度變化看得更清楚——尤其是 🟡 這個 early warning,可以提前數週見到 falsification 的風險。
③ Validated 與 Falsified 均須附明確 cited evidence
新版驗證規則:任何 Falsified 或 Approaching Falsification 判決,必須附上 cited_falsification_URL,不可以僅以敘述文字帶過。Validated 判決同樣需要提供 supporting URL。
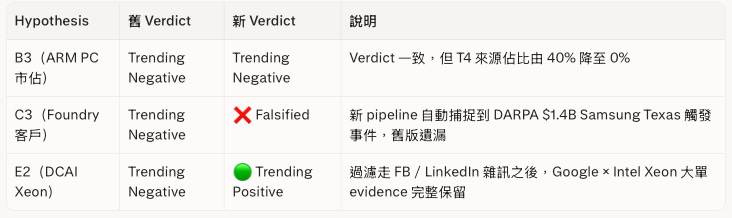
實測結果(INTC Pilot,5/12)
針對污染最為嚴重的 3 個 hypothesis,以新 pipeline 重新執行:
成本透明:INTC 單 ticker run 約 $2.87(舊版約 $1.80),月成本增加約 $425/月。在收入下跌的當下仍然選擇把錢投放於此,是因為我相信 evidence quality 才是90s.pm.investing 唯一應該 compound 的資產 。
用戶端可見的變化
自本週六起,您所追蹤的 ticker 頻道將出現以下變化:
Slack 通知新增 Emoji 標記:🟢 / 🟠 / 🟡 三個新 verdict 指示符
Evidence 來源更為乾淨:不會再見到 Threads、X 或本人 Substack 被 self-cite
Verdict 轉變更為細膩:例如由 ⚪ 過渡至 🟢,代表由「暫無定論」逐步向 Validated 推進
Falsification 早期預警:🟡 Approaching Falsification 會比 ❌ Falsified 提早數週出現
配合
/tree互動查閱:v2 的 stock tree bot 會同步反映最新 6-level verdict,按需 deep dive 任何一片葉
最後
寫到這裡,其實最想講的還是開頭那一句——離開 Threads、收入下跌、但生產力反而爆發、系統連續由 v1、v2 升級到 v3。這種看似矛盾的曲線,只有親身走過一次才會明白是怎樣一回事。
我不敢講自己已經看透一切,但我知道一件事:能夠把錢投進 tokens、把時間投進寫作的那份底氣,完全來自各位讀者。沒有你們,這條路我一個人走不下去。
如果之後您見到任何 verdict 與自己的直覺有出入,請務必回覆或 DM 告訴我——這些 edge case 對模型 calibration 非常有用,亦是我繼續在這條路上走下去的最大動力 🙌
很喜歡這句話"evidence quality 才是90s.pm.investing 唯一應該 compound 的資產 "。謝謝你的付出👍
看了很激勵人心! 厲害👍🏻