
MongoDB, Inc. (MDB) - 我們畫樹
資料庫公司,還是 AI 時代的統一資料底層?假設驅動 |相互獨立 |完全窮盡


一、MongoDB 是誰?
從 schema-free 到 AI Agent 的資料底層
2007 年,10gen 的創辦人厭倦了關聯式資料庫對應用開發的束縛。傳統資料庫要求開發者在寫第一行程式前,先把所有資料欄位定義清楚——每一次業務需求改變,就是一次代價高昂的 schema 遷移。10gen 的回答是文件模型:資料以 JSON 格式儲存,欄位可以即時增減,不同筆記錄可以有不同結構。這家公司後來改名 MongoDB,2017 年 IPO,目前收入達 $2.46B、客戶超過 65,200 家,約 75% 的 Fortune 100 企業是其用戶 。stocktitan
今天 MongoDB 的核心引擎是 Atlas——一個完全托管的雲端資料庫服務,採用消費計費模式,用多少付多少。Atlas 佔 FY26 總收入約 71%,Atlas Q4 FY26 年增 29% 至 $502.6M 。自管版本 Enterprise Advanced 仍存在,但正逐步退居配角。investing
為什麼 AI 時代需要一個新的資料底層
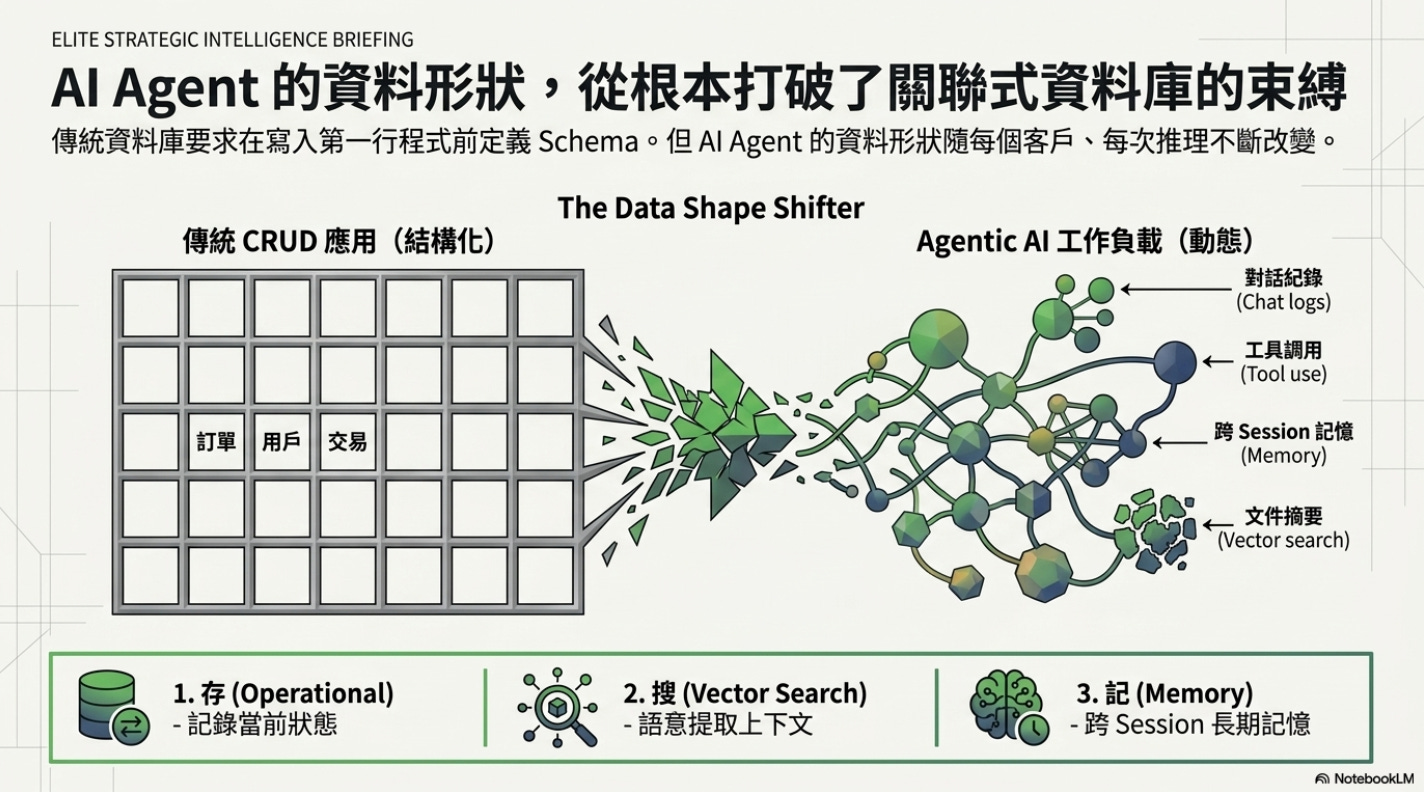
要理解這棵樹所提出的假設,先要理解一件事:AI Agent 的資料需求形狀,與傳統應用完全不同。
傳統應用的資料是結構化的——訂單、用戶資料、交易紀錄,schema 穩定,關聯式資料庫應付自如。但一個 AI Agent 需要處理的是:對話紀錄、工具調用日誌、推理過程的中間狀態、文件摘要、跨 session 的長期記憶。這些東西沒有固定欄位,每個 Agent、每個版本、每個客戶的資料形狀都在變。
更重要的是,一個 AI Agent 同時需要對資料做三件事:
存(operational data):記錄當前對話、工具結果、agent 狀態
搜(vector search):用語意相似度從龐大的知識庫找回相關上下文
記(memory):跨 session 保留長期知識,讓 Agent 「記得」過去的互動
傳統的做法是湊系統:用 Postgres 存 + Pinecone 做向量 + Redis 做 memory,三個系統各有 API、各有 schema、各需同步。資料不一致、延遲、維運成本,是每個 AI 工程團隊都在抱怨的問題。
MongoDB 的主張是:一個 Atlas 實例,同時做完「存+搜+記」。2026 年 5 月,MongoDB 宣布 Atlas Vector Search 整合自動化 Voyage embeddings,MongoDB CEO CJ Desai 的原話是:「要在規模上信任一個 Agent,它必須取得正確的上下文、跨 session 保留記憶、以機器速度運行——資料層是運行 AI Agent 最難的部分。」constellationr
為什麼現在是問這個問題的時機
2025 年 8 月,MDB 單月上漲 67%——市場貼上「AI 基礎設施贏家」標籤。2026 年 3 月 3 日,MDB 單日下跌 25–27%——市場撕掉標籤,換上「成長正常化的成熟 SaaS」。兩次劇烈波動之間,股價從 $420 跌回 $236,估值框架從 EV/Revenue 切換至 P/E 。
這不是隨機波動。這是市場在對同一個問題來回投票:MongoDB 到底是哪種公司? 兩次框架切換之間,真正尚未被獨立檢驗的命題才浮現出來。
二、它靠什麼賺錢?
消費引擎 Atlas
MongoDB 的商業模式是消費計費(consumption-based)。客戶不買年授權,而是按照實際的讀寫量、儲存量、向量搜尋次數付費。這意味著收入與客戶的業務量直接掛鉤——客戶業務爆發,MongoDB 的收入自動放大;客戶縮減預算,MongoDB 的收入也立即下滑。
FY26 全年收入 $2.46B,其中 Atlas 約佔 71% 。Q4 FY26 數據:總收入 $695.1M(YoY +27%),Atlas 收入 $502.6M(YoY +29%)。非 GAAP EPS $1.65,超預期 $0.17,Rule of 40 達標 。客戶總數 65,200+,年化 ARR 超 $100K 的客戶有 2,799 家。
兩台引擎,一台在轉型
Atlas 是成長引擎,但收入組成正在發生質變。傳統 CRUD 應用(增刪查改)是歷史基礎,AI 工作負載(向量搜尋、Agentic 記憶、embedding 推理)是邊際增量。目前 MongoDB 尚未獨立披露 AI 工作負載佔 Atlas 收入的比例——這個「不可見」本身,是本研究最核心的資訊不對稱之一。
