從 GPU skill 到 CPU codebase
無聊的技術手札 01


這篇純粹想記下這個星期做完的一段技術遷移。對我自己是一個分水嶺,對正在讀 Slack 的你,也許能解釋最近 weekly update 的樣子為何變了。
舊版本:一個 agent 食盡所有工序
最初的 stock tree bot 其實非常簡單。
我寫了一個 skill,每個星期日由 Perplexity 的 Sunday batch dispatcher 自動觸發。Dispatcher 拿著我預先排好的 ticker 清單,逐隻股票開一個全新的 LLM context,由一個 AI agent 從頭跑到尾——搜新聞、抽出與每條 hypothesis 相關的訊號、下 verdict、寫 conclusion、組成 Slack 訊息、推上頻道 。
整條 pipeline 就是一個 agent 從頭包到尾。靠的是 prompt engineering,把所有指令塞進一次 LLM call 裡面。
這個版本上線後跑了好幾個禮拜,確實 work。但跑得越久,越多問題慢慢浮上來。
第一,cross-contamination。 Agent 在同一個 context 裡同時處理一隻股票樹的所有 hypothesis。樹有 A、B、C、D 四條 branch,每條 branch 下面有 3 至 6 條子 hypothesis,加起來十幾條。當 LLM 要在同一個 context 裡同時判十幾條,新聞之間會互相干擾——一條與 H-A1 高度相關的新聞,LLM 可能誤用來支持 H-D2;一條本來只是雜音的新聞,因為「看起來像在講同一家公司」就被當成 evidence。每一條 hypothesis 的判斷都不夠深,也不夠獨立。
第二,記憶只能靠 context 撐。 舊 evidence 與 version history 全部塞在 context 裡。每一週的更新都需要參考過去幾週累積的證據,但 LLM context 有上限,新證據進來,舊證據就要被壓縮、被摘要、甚至被 drop。跑久了,LLM 自己都記不住兩個月前對同一條 hypothesis 寫過什麼結論,有時候會自相矛盾。
第三,對讀者而言是個黑盒。 每週看到的只是「H-A1 ✅」「H-B2 ⚠️」這種結果,完全不知道本週實際拉了多少條新聞、哪些被採納、哪些被 drop、為什麼某條 hypothesis 從正面變成中性。沒有透明度,讀者只能選擇相信或不相信 。
第四,與 Perplexity dispatcher 綁得太死。 Dispatcher 出問題,所有股票一起停;想加一隻新股票,就要去改 dispatcher 的 ticker list;想看 run log,基本上沒有——只剩最後 Slack 的成品。

這些問題堆到某個臨界點,我決定要重寫。
新版本:把 agent 拆散到 CPU codebase
新版的根本想法其實很簡單:把一條 monolithic 的 LLM pipeline,拆成一條 deterministic 的 Python pipeline,只在真正需要 judgment 的步驟才呼叫 LLM。
整個系統搬到了 GitHub 一個 repo (/stock-trees),每隻股票自己一個資料夾,裡面有branch.yaml 描述樹的結構、下面每條 hypothesis 一個 JSON 檔(baseline data、verdict、conclusion、past evidence 都在裡面)。每隻股票還有一個獨立的 GitHub Actions workflow,星期六固定時間由 cron 自動觸發。
跑起來的順序如下:
抓新聞:Tavily API 用一組固定 query 抓本週與這隻股票相關的新聞,存成{ticker}_news.json。純 deterministic code,沒有 LLM。
Dispatch 到每條 hypothesis:Python helper 把每條新聞分派到「最相關的那條 hypothesis」;真的找不到 mapping 就丟進 reviewed_low(相關但 confidence 低)或 filtered(拉錯了、與本股無關)。同樣純 code。
逐條 hypothesis 獨立做 judgment:整個系統最關鍵的一步。每條 hypothesis 開一個獨立 LLM call,送一個我叫它 judgment_pack 的 payload 進去——那條 hypothesis 的 baseline data、過去最近一次的 conclusion、past evidence 的壓縮 summary、本週新拉的 evidence。LLM 只專注判這一條,輸出新的 verdict 與新的 conclusion。十幾條 hypothesis 就十幾個獨立 LLM call,context 互不干擾。
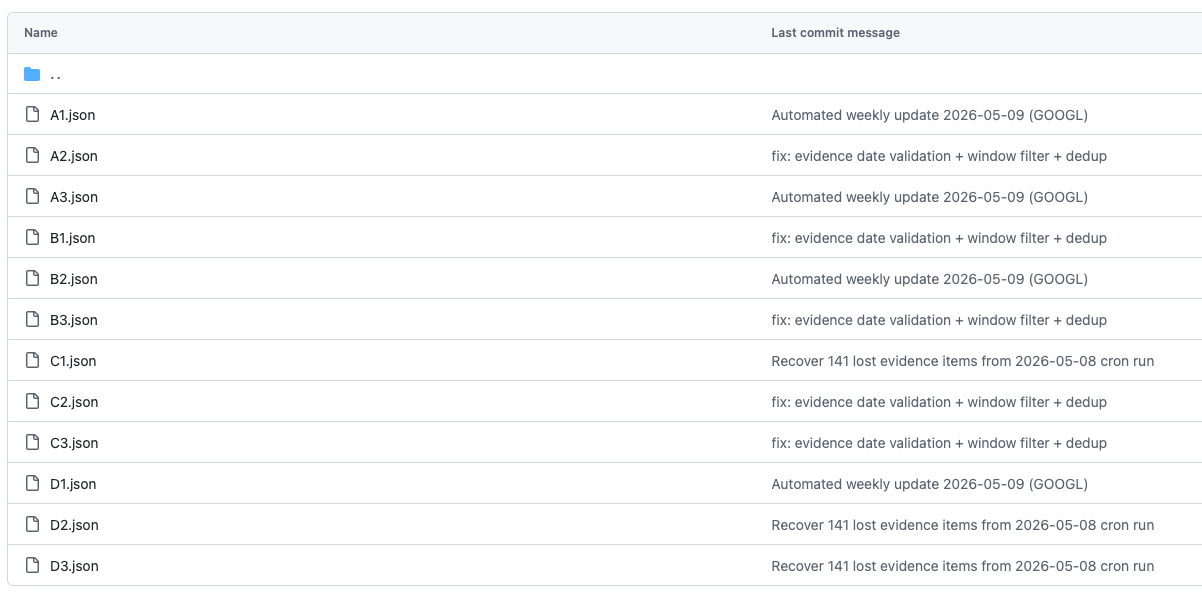
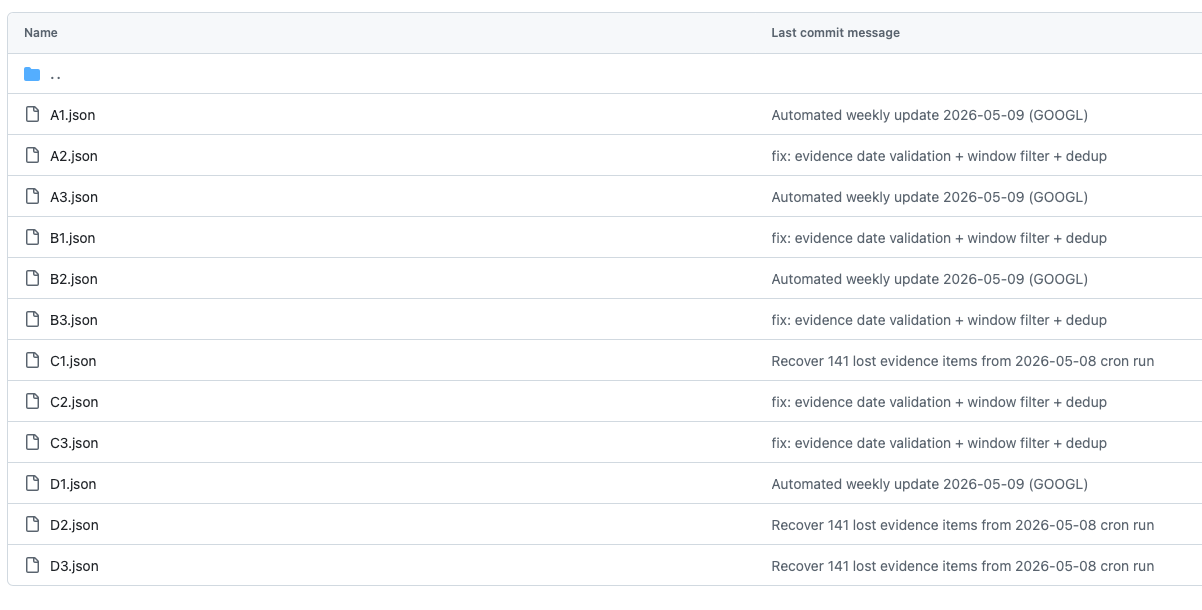
Apply patch + commit:Python 把所有 LLM 回覆 merge 回 JSON,做 schema validation,然後 commit 回 Git。所有歷史版本都在 git log 裡,要追溯任何一條 hypothesis 在任何一週的狀態,git checkout 就可以。
格式化推 Slack:純 code 把所有資訊組成一條 Markdown 訊息,推到對應的 Slack channel 。
整條 pipeline,LLM 只負責第 3 步。其餘所有步驟——抓新聞、分派、validate、commit、推 Slack——全部都是 deterministic Python。GPU 用得少了,CPU 用得多了。
對讀者而言有什麼不同
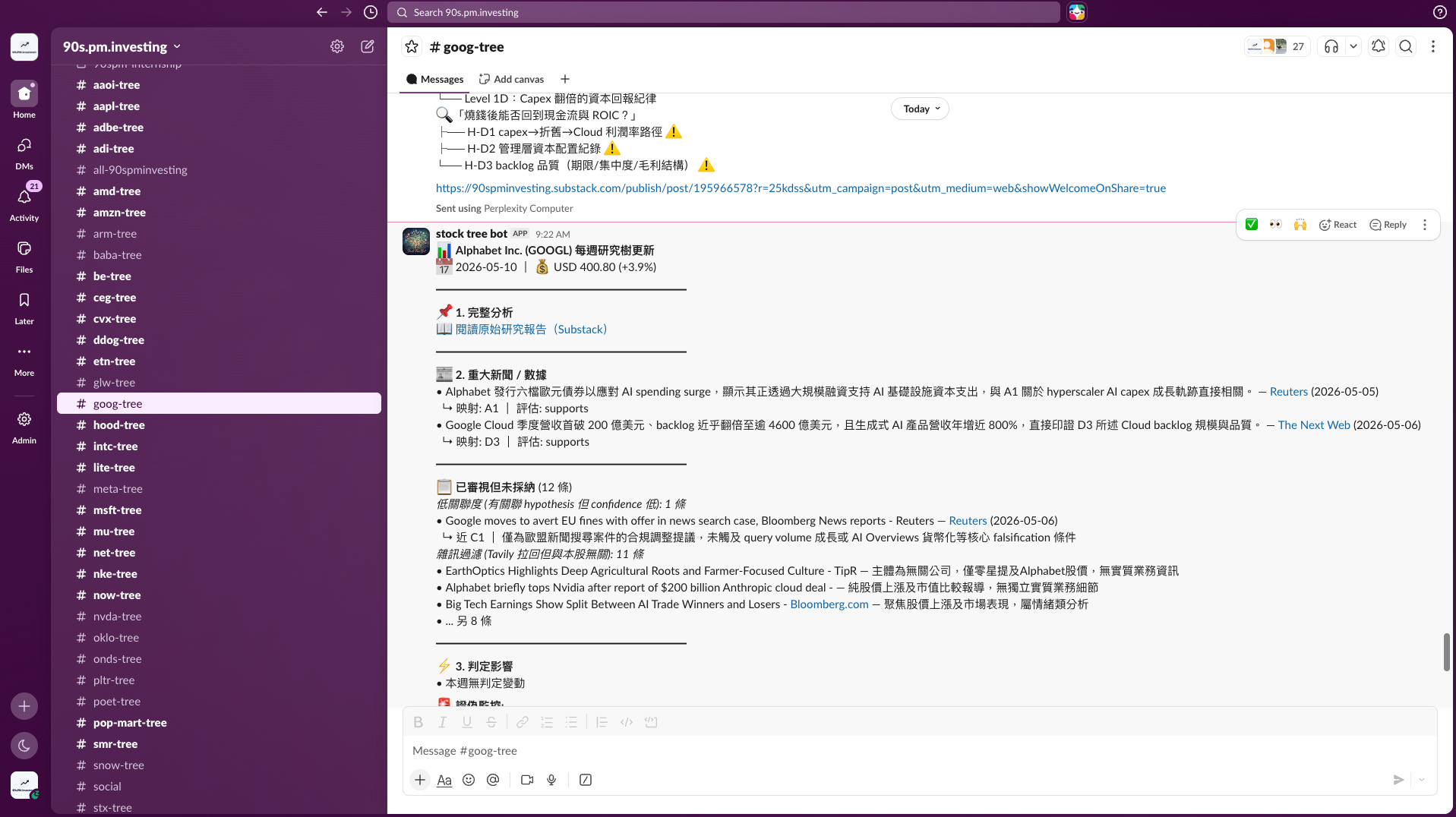
1. Slack 會顯示本週拉了什麼新聞、什麼雜音被過濾。
每週的 Slack 訊息現在會明確列出本週進入 pipeline 的新聞,以及哪些被分到 reviewed_low、哪些被分到 filtered 。讀者可以親眼看到 pipeline 的選材過程。透明度從零變到一百。(順帶一提,這部分昨天才剛調整過,每個 bucket 最多顯示 3 條,避免訊息太長;完整清單一樣 commit 進 audit log,只是不在 Slack 上全部列出。)

2. 每條 hypothesis 都有獨立 agent、獨立 context,判斷準確得多。
這一點我自己用下來感受最深。舊版那種「一個 LLM 同時看十幾條 hypothesis」的做法,實際上很容易 cross-contaminate;新版每條自己一個 LLM call、自己一份 judgment pack,LLM 只需要專注做一件事。判斷的銳利度與一致性都明顯提升。
3. 每個子 level 有 conclusion,每個大 level 有 summary。
舊版 Slack 訊息只有一個 emoji,讀者要自己腦補。新版每條子 hypothesis 後面都會跟一句 ↳ conclusion,是 LLM 本週實際寫的判斷;每條大 branch 也有一段 italic summary,讓讀者看到整條 branch 的總命題。整棵樹是讀得懂的,不需要猜。

4. 所有 version history、past evidence 都進了 Git,LLM 不必再靠 context 回想。
舊版 LLM 要回憶兩個月前的 evidence,只能靠塞在 context 裡的摘要;新版每條 hypothesis 的歷史 evidence 是 commit 在 Git 裡的 JSON,任何時候要看哪一週的狀態都查得到。LLM 做 judgment 時,讀到的是真實、可驗證的歷史資料,而不是它自己的記憶 。
技術逸事
一、Evidence compression
每條 hypothesis 每週都會新增 evidence,跑久了 history 會越來越大。但 LLM context 有上限,不可能整個歷史一字不漏餵進去。
我最初試過很激進的 counts-only summary——只給 LLM 看「過去 8 週新增 12 條 supportive、3 條 contradicting」這類數字,結果 LLM 嚴重 over-react 本週新聞,因為它看不到歷史的具體內容,只能根據本週幾條新聞下判斷,結論飄來飄去。
最後定下來的設計叫 fat judgment_pack:每次 LLM call 餵進去的是 baseline data(固定不變的命題基準)+ 過去最近一次 conclusion + past evidence 的壓縮 summary + 本週新拉的 evidence,全部 freeze 在 JSON 裡。一隻股票大約 33KB,128K context 完全吃得下。Pack 變肥了,但 LLM 的判斷穩定多了,不再 over-react。
二、Pipeline reliability
37 隻股票每個禮拜六同時跑,偶爾會出各種小問題:GitHub Actions runner timeout、Tavily rate limit、回 malformed JSON、shell pipefail 漏掉 silent failure。
處理方法全部都是工程上的笨功夫:
每個關鍵 step 加 retry + timeout
所有 LLM 回覆做 JSON schema validation,fail 了就走 fallback path
每次 run 把所有中間 artifact(news.json、patch.json、audit_log.json)upload 上去,出事後可以 download 下來做 post-mortem
Workflow 加 pipefail,確保 shell pipeline 任何一段 fail,整個 step 都 fail,不會 silent pass
最後是 monitoring:每個禮拜六我自己會 check 一次 Slack channel,確認 37 條訊息都正常推出;若有 channel 沒訊息,就回 GitHub Actions 看 log
這部分沒什麼好聽的故事,就是一堆 commit、一堆 incident review,慢慢把 reliability 推高。
(昨天剛好踩到一個挺有趣的 case:我想驗證新格式,手動同時觸發 37 個 workflow,GitHub Actions 直接 cancel 掉 35 個,連 job 都沒派下去。推測是 Pro account 一個沒公開的 concurrency cap。後來改成串行一個一個觸發就 100% 成功。禮拜六 cron 因為 schedule 已經 stagger 過,理論上不會撞到這個 cap——下個禮拜六會驗證。)
從 Agent 到系統
寫到這裡有點感慨。
過去這一年,我慢慢從「砌一個 AI agent」變成「砌一個包住 AI 的系統」。
舊版的 stock tree bot,核心是一個 agent,所有事情都由 agent 去做。當時我的心態是:LLM 越強,系統就越強。所以我把所有東西塞進一個 prompt,期待 LLM 能在一個 context 裡端到端解決所有問題。
新版不是這樣。新版裡 agent 還是那個 agent,但它已經不再是主角——它只是 pipeline 其中一個 step,前面有 deterministic code 餵它資料,後面有 deterministic code 接它的 output 做 validation 與 commit。它的責任邊界變得非常明確:只做 judgment,不做 dispatching、不做 storage、不做 formatting、不做 reliability。
這不是因為 LLM 不好,而是單靠 LLM 不夠可靠。一個系統要做到每週都跑、每個讀者都信得過,最後一定要回到工程的本份:分層、隔離、可觀察、可重做、可回溯。AI 負責有 judgment 的地方,deterministic code 負責不應該有 judgment 的地方。混在一起做,最後兩邊都做不好。
從 GPU 為本到 CPU 為本、從 skill 到 codebase、從一個 monolithic agent 到一個包住 agent 的系統——我學一件事:
把 AI 擺回它應該擺的位置。
它是一個很強的 component,但它不是整個系統 。
有興趣的話,按此加入會員